A central pillar of the Web3 vision is "composable data" - the idea that the information that powers our online experiences can be read, remixed, and 'composed on' by applications across the web. This reusable model is in contrast to today's model, where data are primarily trapped in application-specific siloes.
Composable data is a paradigm shift for how the web works because it not only changes how applications are built but what an application is. This post aims to make this shift clear and concrete.
Data: the foundation of most apps
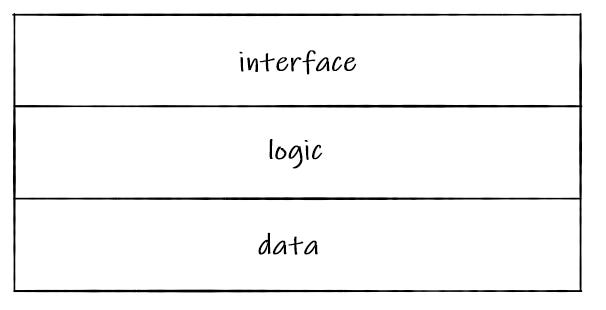
Applications are basically interfaces + some business logic + databases. That's true of the vast majority of products online. The interface is what you see and interact with. The business logic defines and delivers the core functionality. Databases store the information presented, the events that occur, and the record of everything that has happened that might be needed in the future.
In many products, especially highly successful ones, much of the value is in the data. The aggregation of everything that has happened before makes the product increasingly valuable and sticky over time and usage. Interface changes are frequent. New logic and services are constant. However, the data are persistent and ever-growing. Facebook, Twitter, or Airbnb all change their UIs all the time, tweak their feed algorithms, and update their services (Marketplace, Spaces, Experiences). It’s the friends, personalization, and network of content (posts, tweets, rentals) that compounds.
This applies in the vast majority of cases. Some exceptions seem like pure services. Zapier, for example, is mostly logic that connects others' databases through APIs. But even here, your built-up Zaps are stored in their database and make it less likely you'll switch to IFTTT. Plaid connects financial databases, but the authorizations are stored on their server so you don’t have to reconnect every time.
Databases today are painfully siloed
Today, databases are basically siloed — every application has its own. This has many bad implications: redundant infrastructure, honeypots of data with poor security, fragmented data. It also means that every application must have its own database to feed its logic and its interface. The 3 layers — interface, logic, and database — have to be bundled by every application.
This basic stack is so accepted (and frankly so much easier now with cloud services) that we rarely question it. But it's ridiculously inefficient. Why should every potential business need to build all 3 parts of this stack when their core innovation or value add comes primarily from one or two? If an entrepreneur has a vision for an improved service or interface, she can't just build that. She has to build the whole stack - from scratch - and compete on all of it.
One direct consequence of this is far fewer things get built or used. Because data is the foundation for so much value over time, and because it's so much more valuable when networked with other data (network effects, big data, etc.), there's far less aggregate value when data is spread across more fragmented databases and applications.
This creates a natural limit to competition and natural suppression of innovation. Any given database is proprietary, controlled by a specific app and siloed off from any other use cases. Only the company that controls that database can build new services or interfaces with it or permit others to do the same. And only in exceptional and intentional cases - one-off integrations or pre-defined APIs - are data shared between products.
For example, in its early days Twitter allowed 3rd parties to build interfaces and apps like TweetDeck and others to give users a different experience of the same ‘tweets’ and ‘followers.’ Then they shut this access down, squeezing those apps out. If you want a different feed algorithm or interface now, you’re out of luck.
Censorship is the removal of things already created and triggers massive uproar. But the hidden and the much larger impact of siloed control is the gatekeeping on innovation: the suppression of things that could never be created in the first place.
Composable data: a new paradigm
When database functionality is not siloed but open, this all changes. Any app can build on the same data. No app is a gatekeeper to it. And not every app needs to build an entire siloed stack.
This enables 'permissionless innovation' - anyone can build any new service (logic) or any new interface (app) on the same data layer. An improved product or feature can come from anyone anywhere (not just the original company), and it just adds to all the existing services and interfaces that can be used. Any developer can build a new interface to see tweets or interact with followers.
Today’s web browsers are relatively composable - you can add new functionality and features with extensions. Imagine if web browsers were locked down, and you had to choose between the core feature set alone: Chrome with built-in casting, Firefox with Pocket, or Brave with a crypto wallet. Thankfully you don't have to choose and be left so wanting because plugins let independent developers add functionality. This is enabled, in part, by the local database built into browsers that new plugins and apps can all leverage. Most apps are the opposite - closed to outside innovation or extension. They are like browsers with locked functionality.
A composable data paradigm makes apps extendible by making the data layer shared across all the apps using it. This means the value of aggregated data and its network effects builds even though the services, logic, and interfaces are more varied. You get the benefits of diversity without the costs of fragmentation. Composable apps are far more likely to be complementary - delivering new services and interfaces to fill an unfilled niche— and far less likely to try to outcompete incumbents on a brand new (heavy, expensive) proprietary stack.
Some simple examples:
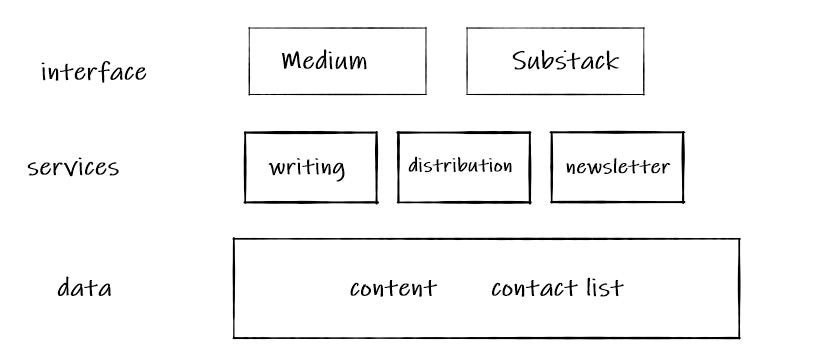
- If Medium were built on open data, Substack wouldn't have to build an editor, interface, and CMS from scratch. They'd build a subscription module that operates on top of the Medium editor and content. You could continue writing in Medium (or elsewhere) and publishing there while using Substack's subscription feature to build an audience and deliver directly to them. (This is what we’re beginning to see with Mirror’s ecosystem with apps for curation, discovery and more.)
- If Notion were built on open data, anybody could be adding features that end up in your Notion board. Currently, there's no good, quick, 'to-do list' in notion. Someone could build a super-fast lightweight standalone to-do list app and have additions sync into the right place you want in Notion. Somebody else could build a tool that generates these notes from a calendar invite or email. This is starting to happen on composable data.
- If Lever or another recruiting platform (or SaaS products generally) were built like this, you wouldn't be locked into their single feature set. We use Lever as it's got an easy-to-use interface, tracks candidates well, and will scale. But I dislike their interviewing and scorecard template. If it were built on open data, we'd build our own scorecard on the same underlying candidate database and be able to add the features we need anytime.
This model's real power is in how fast innovation can happen when new development doesn't require an entirely new stack and data model and when emergent benefits arise from many apps building on the same underlying structure.
Ceramic is building infrastructure for composable data. Within weeks after it became available several developers in the community built two apps with zero knowledge of the other, but instant ability to use and edit the same data.
The power of compounding
Sun Microsystems founder Bill Joy said that "no matter who you are, most of the smartest people work for someone else.” With permissionless innovation, all these people can work together and drive a dramatically faster pace of innovation.
The need for "10x" improvements on products falls away because there's so little switching cost between applications - the underlying data stays the same. Every experience can be constantly improving, with iterations coming from anyone rather than only the original creator or company. The web becomes more composable, with more builders.
The net effect is a flywheel driving apps and experiences online to far greater heights. More apps building on the same data leads to more (and more valuable data), which enables better experiences, which attracts more developers to build more apps, and so on.
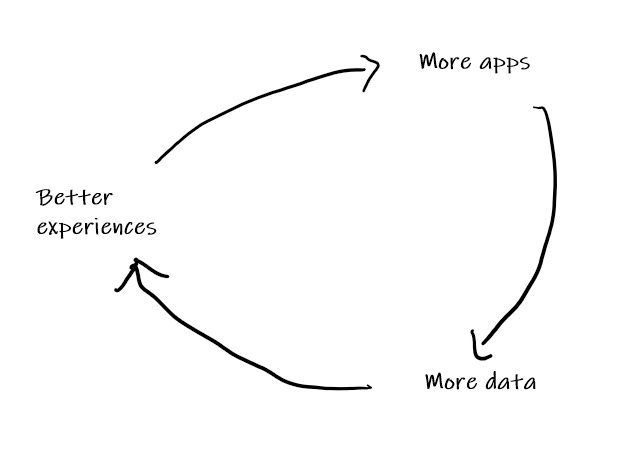
Applications no longer need to build an entire stack and compete for the best underlying data. Instead, anyone with an idea for improving the features, services, or interfaces of a use case can plug into the existing ecosystem and its data and start offering their improvement. Builders can build faster, users get more choice, and the Web as a whole accelerates through rapid, permissionless innovation.